Nature Cam is a node.js/express web application that dynamically queries and displays nature and animal YouTube live videos from a curated selection of channels. Leveraging the YouTube Data API, this application fetches live video content and maps each video's location using MapTiler and Leaflet. To optimize performance, the application integrates Redis caching to efficiently manage API requests, ensuring that repeated requests for the same data are swiftly served from the cache. Additionally, the project incorporates backend caching for Spotify API calls, enhancing overall responsiveness. The core of this project includes a combination of powerful technologies such as the Google Geocoding API, spaCy for natural language processing, and a comprehensive setup involving Webpack, Express, and Python for location data extraction and validation. The frontend of the application presents a user-friendly interface, complete with embedded videos, location details, and interactive map visualizations.
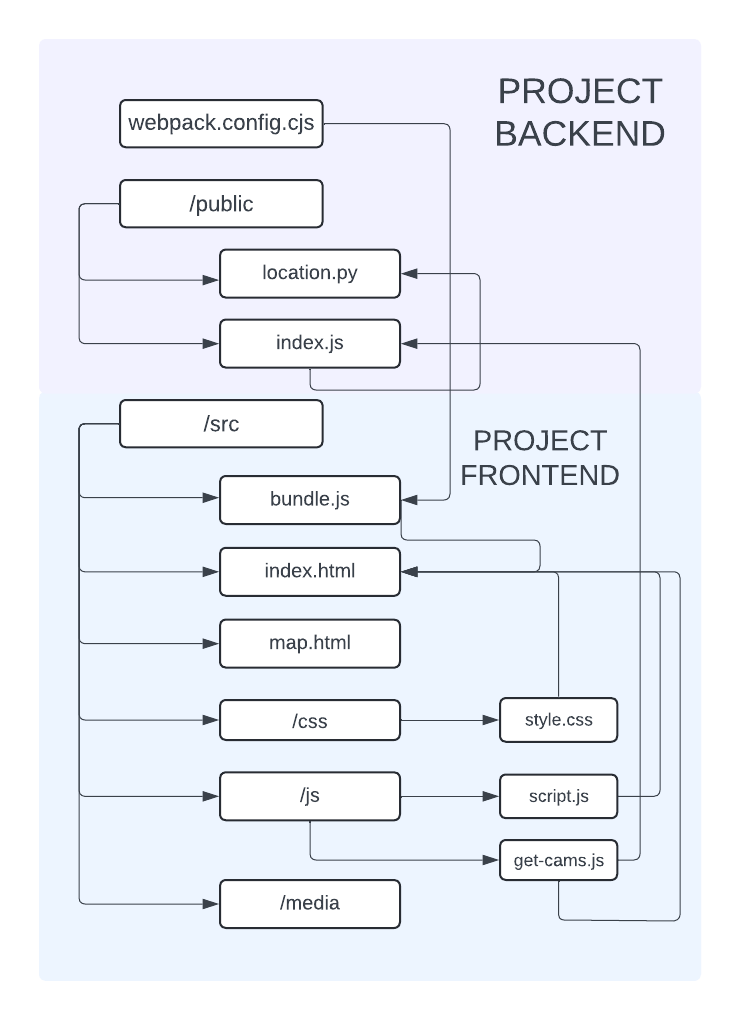
A `webpack.config.cjs` file is a configuration file for Webpack, a popular module bundler for JavaScript applications. It defines how Webpack should process and bundle the project's assets, such as JavaScript files, stylesheets, and images. The file uses the CommonJS module syntax, as indicated by the `.cjs` extension. The configuration begins with importing necessary modules: `path` for file path manipulation, `HtmlWebpackPlugin` to generate an HTML file and handle HTML assets, `NodePolyfillPlugin` to polyfill Node.js core modules for browser environments, and `webpack` for access to Webpack's built-in plugins and utilities. The `entry` point is set to `./public/js/get-cams.js`, specifying the main JavaScript file for Webpack to start from. The `output` configuration defines the output directory as `public`, the output bundle name as `bundle.js`, and the `publicPath` as `/`.
The `module` rules specify how different types of files should be processed. JavaScript files are processed using `babel-loader`, which transpiles ES6+ code to ES5 using the `@babel/preset-env` preset and `@babel/plugin-transform-runtime` plugin, while excluding the `node_modules` directory. Node files with the `.node` extension are processed using `node-loader`, and TypeScript definition files with the `.d.ts` extension are ignored using `ignore-loader`. The `resolve` configuration specifies file extensions Webpack should resolve and directories to search when resolving modules, with fallbacks provided for Node.js core modules to make them work in the browser.
Plugins extend Webpack's functionality, with `HtmlWebpackPlugin` generating an HTML file based on a template and injecting the output bundle at the end of the body tag, `IgnorePlugin` ignoring the `worker_threads` module, and `NodePolyfillPlugin` providing polyfills for Node.js core modules in browser environments. Finally, the `mode` is set to `development`, optimizing the build for development by enabling features like source maps and more detailed error messages.
`index.js` is a server-side application built using the Express framework, designed to manage web requests and execute backend logic efficiently. The script begins by requiring essential dependencies such as `core-js/stable` and `regenerator-runtime/runtime`, which provide modern JavaScript functionalities and enable asynchronous programming with Promises and async/await syntax. It also requires `dotenv` to manage environment variables securely, allowing sensitive data like API keys to be stored outside the source code.
An instance of the Express application is created, and it is configured to listen on a specified port, defaulting to 5000. A Redis client is initialized to connect to a local Redis server at `redis://localhost:6379`. The application sets a cache expiration time of 300 seconds (or 5 minutes) for caching results, allowing for efficient data retrieval while reducing the load on the server. The script utilizes middleware functions such as `cors()` to enable Cross-Origin Resource Sharing, and `express.json()` to parse incoming JSON requests.
Upon establishing the Redis connection, the script listens for connection events, logging a success message when the client connects and any errors encountered during the connection process. A crucial part of the script is the cleanup of the `index.html` file located in the `public` directory. It reads the file and removes any previous script tags that refer to `bundle.js` using a regular expression. If successful, it writes the cleaned HTML back to the file and logs the result.
After cleaning the HTML, the Redis client connects, and the script initiates the Webpack bundling process using the provided `webpack.config.cjs` configuration file. If the bundling is successful and there are no errors, the Express server starts listening for incoming requests, and a message indicating the server's running status is logged. The application serves static files from the `public` directory, allowing clients to access assets such as HTML, CSS, and JavaScript files. The root endpoint (`/`) serves the main `index.html` file, while additional API endpoints are defined to provide access to API keys for services like MapTiler and YouTube. These endpoints respond with JSON objects containing the respective keys, facilitating integration with third-party services.
The `/callPythonFunction` endpoint is designed to handle POST requests for executing specific Python functions. It expects a JSON payload containing a `functionName` and an array of parameters (`param`). The input is validated to ensure that both fields are present and that `param` is an array. A cache key is generated based on the sanitized function name and parameters, allowing for efficient retrieval of cached results. Before executing the Python script, the script checks the Redis client connectivity and performs a ping to confirm the client is open. It then attempts to retrieve the cached result associated with the generated cache key. If a cached result is found, it is returned immediately as a JSON response. If not, the script constructs a command to execute a Python script located in the `python` directory. This command uses `execSync` from the `child_process` module to run the script synchronously, capturing its output for further processing.
After executing the Python script, the resulting output is cached in Redis with an expiration time defined earlier. The output is parsed and returned as a JSON response. The script includes comprehensive error handling to log and manage issues related to file operations, Redis commands, and Python script execution, ensuring robustness in various scenarios. Finally, the script listens for a `SIGINT` signal, allowing for graceful termination of the server. Upon receiving the signal, it disconnects the Redis client and logs a message indicating that the client has been disconnected, ensuring that resources are cleaned up properly before the application exits.
The provided Python script is a sophisticated tool for extracting and validating location information from textual captions. It leverages several libraries and techniques to perform its tasks efficiently. The script starts by importing necessary libraries, including `spacy` for natural language processing, `requests` for making HTTP requests, and `geopy` for geocoding. It also incorporates concurrency with `ThreadPoolExecutor` to handle multiple tasks simultaneously, enhancing performance.
The core function, `find_naturecam_locations(captions)`, processes a list of captions to extract and refine location data. It first defines `process_locations(locations)`, which filters out `None` values and identifies the most accurate location based on the length of addresses and names. If duplicates are found, it selects the most specific one. To generate potential location names, `generate_combinations(source)` creates consecutive word combinations from a given text. The function `generate_substrings(sentence)` further processes sentences to generate and validate substrings that might represent locations. This function cleans the sentence, splits it into words, and constructs substrings of varying lengths, checking for capitalization and validating these substrings as location names. Locations are extracted using `extract_locations(text)`, which utilizes SpaCy's named entity recognition to identify geographic and organizational entities. For validation, `validate_locations(text)` makes HTTP requests to the Google Maps Geocoding API to verify location names, while `get_location_info(location)` retrieves detailed location data, including coordinates and formatted addresses.
To handle potential duplicates, `single_location(locationData)` checks for duplicates in both location names and addresses, prioritizing the most specific or longest address. This ensures the most accurate location is selected. The script processes each caption concurrently using `ThreadPoolExecutor` in `process_caption(caption)`, which extracts locations, generates additional data, and appends the results. It aggregates all processed data and resolves it to a single, accurate location. Finally, the script's command-line interface reads JSON input, invokes the main function, and prints the results or errors. It ensures robust error handling and provides clear output formatting. The script effectively combines natural language processing, geocoding, and concurrency to extract and validate location information from textual captions, demonstrating a comprehensive approach to data processing and validation.
The main page features four live cam videos displayed simultaneously. When users hover over a video, the location name and address appear. At the top and bottom of the page, navigation buttons are available, including one that directs users to the map page, where all current live cams are geographically pinpointed on a 2D map. An index button provides a list of active live cams, complete with video titles and hyperlinks to their respective YouTube channels. A sound button allows users to mute or unmute all videos, while a shuffle button refreshes the page with four new live cams. Finally, an info icon reveals a brief description of the site upon hover.
The provided JavaScript script is designed to initialize a YouTube live video application that fetches and displays live videos from a specified set of YouTube channels. It begins by defining an array of column names for potential CSV data output, which includes fields such as "videoID," "videoTitle," "videoChannelName," "videoDescription," and location-related details. Key constants are established, including an array of YouTube channel IDs to query, a maximum results limit of one video per channel, cache expiration time set to 300 seconds, a daily query limit of 100 to prevent exceeding API request quotas, and local storage keys for tracking the number of queries made and the last reset date for the daily limit.
The script fetches the YouTube API key from a server endpoint (`/api/youtube-key`) using the Fetch API. Upon successful retrieval, the key is stored in a variable called `API_KEY`, allowing the script to make authorized requests to the YouTube Data API. The script also accesses various DOM elements, such as video iframes and location information placeholders, to display the video content and associated details. A key function in this script is `callPythonFunction`, which asynchronously sends a POST request to a Python backend endpoint (`/callPythonFunction`). This function takes parameters related to video titles and descriptions and retrieves location data based on these parameters. Error handling is included to manage network response issues.
The `fetchLiveVideos` function is responsible for fetching live video data from YouTube channels. It first checks and updates the daily query count stored in local storage, resetting the count if the date has changed. If the daily limit of queries has been reached, an error is thrown. The function also implements a caching mechanism using session storage, ensuring that if data for a channel is already available, it can be retrieved without making a new API request. If the data is not cached, the function makes a request to the YouTube API to search for live videos by channel ID. If successful, it subsequently fetches detailed information about the videos to filter out those that are region-restricted.
The `getFullVideoInfo` function enriches the fetched live video data by calling `getLocations`, which uses the previously defined `callPythonFunction` to obtain geographical information related to each video. This function processes the title and description of each video to extract potential location data. If no location data is found, it returns default values, including empty strings and zeros for location coordinates. The results are then pushed into the `liveVideos` array for later use. To load and display the videos, the `loadInitialVideos` function populates the video iframes with the source URLs for the first four videos in the `liveVideos` array and updates various DOM elements with location information, including the name, coordinates, and address of each video's location. Additionally, a shuffle button is set up to allow users to randomize the displayed videos by selecting different entries from the `liveVideos` array.
Upon loading the window, the script checks for cached video data in local storage and determines whether it is up to date based on a timestamp. If the cached data is current (not older than 12 hours), it uses that data to populate the video display. Otherwise, the script iterates through the specified channel IDs, fetching live videos, enriching the information with location data, and updating local storage with the newly retrieved data. This approach not only minimizes unnecessary API calls but also ensures that the application presents an organized and interactive view of live videos and their associated locations efficiently.
The map page was designed to integrate the interactive map using Leaflet, a popular JavaScript library. A back button allows users to navigate to the main page, while a full-screen div designated for the map display and an information box showcase details about videos associated with specific map locations. The information box displays the video title, description, location name, and an iframe for video streaming. The core logic initializes the map, adds markers based on a dataset stored in local storage, and handles user interactions. Each marker features a tooltip with the video title and supports mouseover and click events for enhanced interactivity. Users can navigate through different videos using left and right arrows, updating both the map view and information displayed in the info box.